|
Pré-processe seus dados antes da construção de modelos
Para usar algoritmos desenhados para atributos nominais (como os modelos Naïve Bayes e logito), você deve criar faixas para suas variáveis escalares antes da construção do modelo. Se elas não forem transformadas em faixas, algoritmos como regressão logística multinomial levarão muito tempo para processar ou eles podem não convergir. Especialmente se você tiver um conjunto de dados grande. Além disso, os resultados que você recebe podem ser �difíceis de ler ou interpretar.
O IBM SPSS Data Preparation Optimal Binning, no entanto, permite determinar pontos de corte para ajuda-lo a alcançar o melhor resultado possível para os algoritmos desenhados para usar atributos nominais.
Com esse procedimento, você pode selecionar entre três tipos de criação de faixas para pré-processar os dados:
> Não supervisionada - cria faixas com a mesma frequência
> Supervisionada - leva a variável dependente em conta para determinar pontos de corte. Esse método é mais preciso que o não supervisionado; no entanto, é também mais intensivo computacionalmente.
> Abordagem híbrida - combina as abordagens não supervisionadas e supervisionadas. Esse método é particularmente útil se você tem um grande número de valores distintos.
|
Expanda suas técnicas de preparação de dados com o IBM SPSS Data Preparation
Utilize as técnicas de preparação de dados especializadas do IBM SPSS Data Preparation para facilitar a preparação de dados no processo analítico. O IBM SPSS Data Preparation se conecta facilmente ao IBM SPSS Statistics Base assim você pode trabalhar perfeitamente no ambiente IBM SPSS.
Execute verificação de dados
A validação de dados tem sido tipicamente um processo manual. Você pode executar uma frequência nos seus dados, imprimir as frequências, marcar o que precisa ser arrumado e verificar os IDs dos casos. Essa abordagem consome tempo e tende para erros. E visto que todos os analistas da sua empresa poderiam usar um método um pouco diferente, manter a consistência projeto a projeto pode ser um desafio.
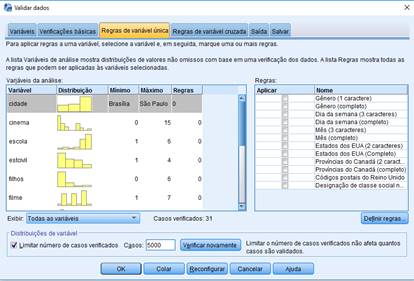
Para eliminar a verificação manual, use o procedimento IBM SPSS Data Preparation Validate Data. Ele permite aplicar regras para executar verificação de dados baseada no nível de medida de cada variável (seja ela categórica ou contínua).
Por exemplo, se você está analisando dados que tem variáveis na escala Likert de cinco pontos, utilize o procedimento Validate Data para aplicar uma regra para escalas de cinco pontos e sinalize todos os casos que tem valores fora da faixa de 1 a 5. Você pode receber notificações de casos inválidos, bem como resumos de violações de regras e o número de casos afetados. Você pode especificar validação de regras para variáveis individuais (como checagem de faixa) e verificação entre variáveis (por exemplo, “aposentados aos 30 anos de idade).
Com esse conhecimento você pode determinar a validação de dados e remover ou corrigir casos suspeitos a seu critério antes da análise.
Encontre rapidamente outliers multivariados
Previna a distorção de análises pelos outliers usando o procedimento IBM SPSS Data Preparation Anomaly Detection. Ele busca por casos incomuns baseado em desvios de casos semelhantes e atribui razões para tais desvios. Você pode marcar ouliers criando uma nova variável. Uma vez que você identifique casos incomuns, você pode analisá-los e determinar se eles devem ser incluídos na sua análise. |









