|
Controle o processo do começo ao fim
Depois de selecionar um procedimento, especifique as variáveis dependentes, que devem ser escaladas, categóricas ou uma combinação dos dois. Você ajusta o procedimento escolhendo como particionar o conjunto de dados, qual tipo de arquitetura você deseja e quais recursos de computação serão aplicados na análise.
Finalmente, você escolhe se você deseja exibir os resultados em tabelas ou gráficos, salvar variáveis temporárias opcionais para o conjunto de dados ativo, e/ou exportar modelos em formato de arquivo baseado em XML para escorar dados futuros.
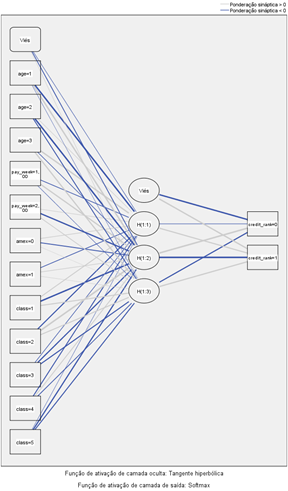 |
Em um processo MLP como o visto aqui, os nós nas camadas de entrada e saída estão conectados aos nós em uma ou mais camadas ocultas. |
| |
|
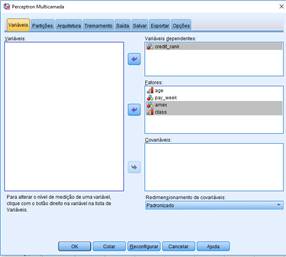 |
Assim como no IBM SPSS Statistics Base ou outros módulos, a partir da caixa de diálogo no IBM SPSS Neural Network, você seleciona as variáveis que deseja incluir no modelo. |
| |
|
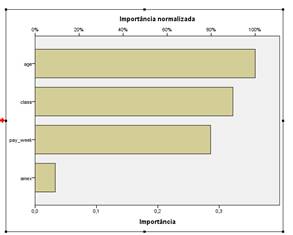 |
Os resultados da exploração de dados com o IBM SPSS Neural Networks podem ser exibidos numa variedade de formatos de gráficos. Esse gráfico de barras simples é uma das muitas opções. |
|
Como você pode utilizar o IBM SPSS Neural Networks?
Você pode combinar o Neural Networks com outros procedimentos estatísticos para alcançar insights mais claros em determinadas áreas:
Pesquisa de mercado
- Criar perfil dos clientes
- Descobrir as preferências dos clientes
Database marketing
- Segmentar sua base de clientes
- Otimizar campanhas
Análise financeira
- Analisar o risco de crédito
- Detectar possíveis fraudes
|
Análise operacional
- Gerenciar o fluxo de caixa
- Melhorar o planejamento de logística
Saúde
- Prever custos de tratamentos
- Executar análises de resultados médicos
|
Use técnicas de data mining
O IBM SPSS Neural Networks oferece uma abordagem complementar às técnicas de análises de dados disponíveis no IBM SPSS Statistics Base e seus módulos. A partir da interface familiar do IBM SPSS Statistics, você pode “minerar” seus dados para encontrar relações ocultas, usando tanto o procedimento Multilayer Perceptron (MLP) quanto o Radial Basis Function (RBF).
Ambas são técnicas de aprendizado supervisionadas - ou seja, mapeiam as relações implícitas nos dados. Ambos utilizam arquiteturas feed-forward, o que significa que os dados se movem somente em uma direção, dos nós de entrada, passando através das camadas ocultas de nós, para os nós de saída.
Sua escolha pelo procedimento será influenciada pelo tipo de dados que você tem e o nível de complexidade do que você procura descobrir. Enquanto o procedimento MLP pode encontrar relações mais complexas, o procedimento RBF é geralmente mais rápido.
Com essas duas abordagens, o procedimento opera em um conjunto de dados de treinamento e então aplica esse conhecimento em todo o conjunto de dados, e para qualquer novo banco de dados. |









